爬虫框架
Scrapy简介
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架
官网:https://scrapy.org/
工作流程
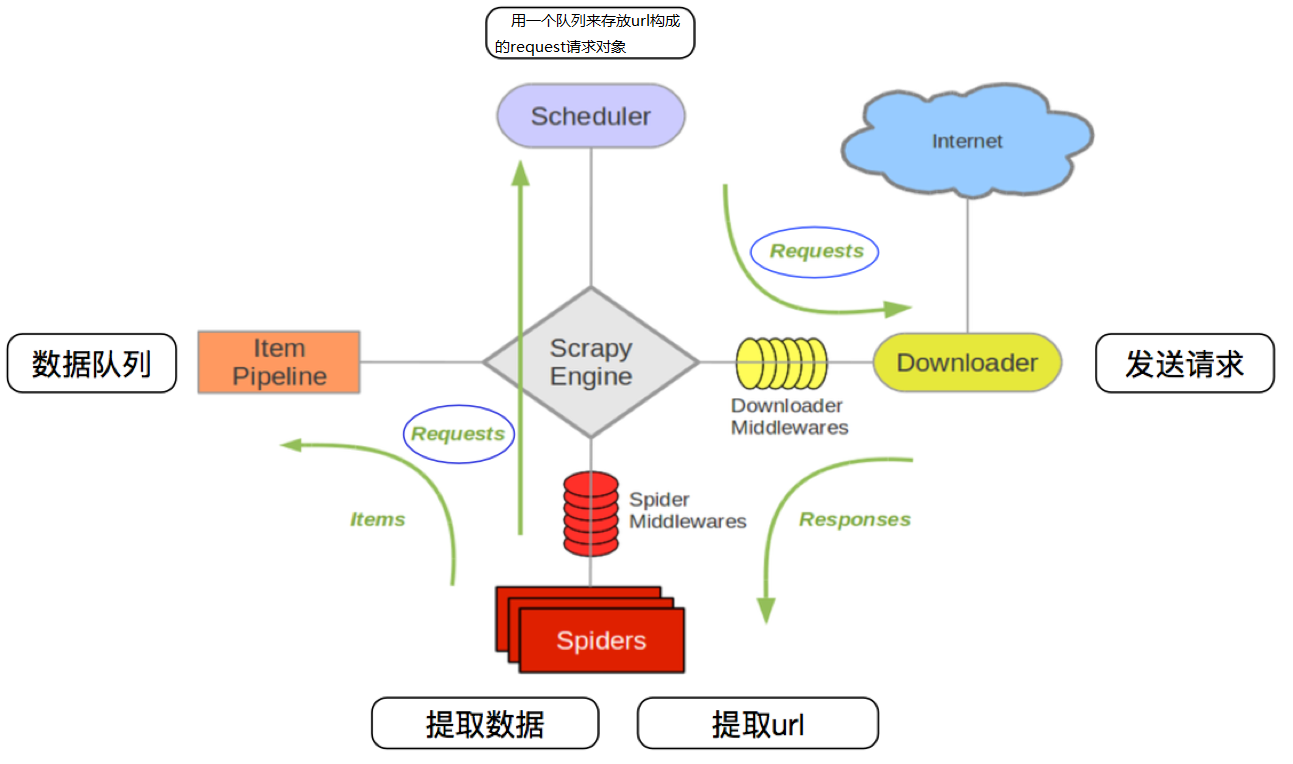
- 爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取response响应—->下载中间件—->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象—->爬虫中间件—>引擎—>调度器,重复步骤2
- 爬虫提取数据—>引擎—>管道处理和保存数据
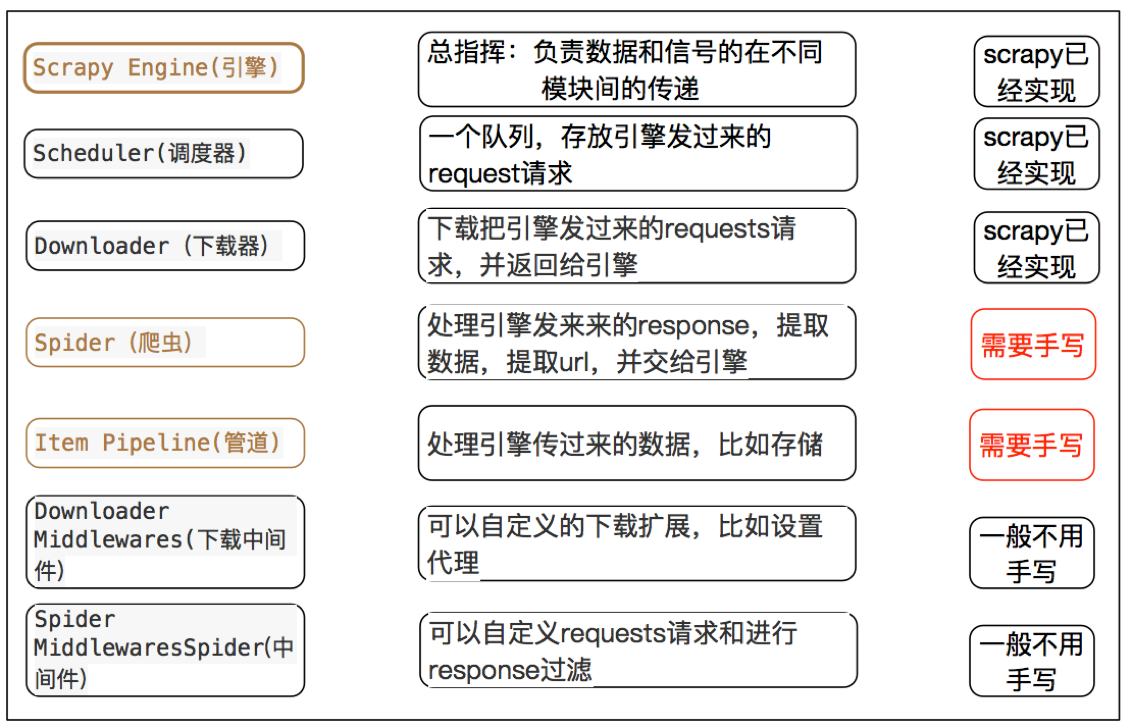
内置对象模块
- request请求对象:由
url method post_data headers等构成
- response响应对象:由
url body status headers等构成
- item数据对象:本质是个字
简单使用
安装:pip install scrapy
创建项目:scrapy startproject 项目名称

生成爬虫:进入项目目录执行scrapy genspider 爬虫名称 允许爬取的域名

启用管道,修改settings.py
1
2
3
| ITEM_PIPELINES = {
'myspider.pipelines.xxxSpider': 400
}
|
运行爬虫:进入项目目录执行 scrapy crawl itcast
小结
- scrapy的安装:
pip install scrapy
- 创建scrapy的项目:
scrapy startproject myspider
- 创建scrapy爬虫:在项目目录下执行
scrapy genspider xx xx.cn
- 运行scrapy爬虫:在项目目录下执行
scrapy crawl xx
- 解析并获取scrapy爬虫中的数据:
- response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
- extract() 返回一个包含有字符串的列表
- extract_first() 返回列表中的第一个字符串,列表为空没有返回None
- scrapy管道的基本使用:
- 完善pipelines.py中的process_item函数
- 在settings.py中设置开启pipeline
- response响应对象的常用属性
response.url:当前响应的url地址response.request.url:当前响应对应的请求的url地址response.headers:响应头response.requests.headers:当前响应的请求头response.body:响应体,也就是html代码,byte类型response.status:响应状态码
管道
管道配置文件是pipelines.py
process_item(self,item,spider):
- 管道类中必须有的函数
- 实现对item数据的处理
- 必须return item
open_spider(self, spider): 在爬虫开启的时候仅执行一次close_spider(self, spider): 在爬虫关闭的时候仅执行一
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import json
from pymongo import MongoClient
class MyFilePipeline(object):
def open_spider(self, spider):
def close_spider(self, spider):
def process_item(self, item, spider):
return item
class MyMongoPipeline(object):
def open_spider(self, spider):
def process_item(self, item, spider):
return item
|
开启管道
在settings.py设置开启pipeline
1
2
3
4
| ITEM_PIPELINES = {
'myspider.pipelines.MyFilePipeline': 400,
'myspider.pipelines.MyMongoPipeline': 500,
}
|
注意
- 使用之前需要在settings中开启
- pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行
- 有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
- pipeline中process_item的方法必须有,否则item没有办法接受和处理
- process_item方法接受item和spider,其中spider表示当前传递item过来的spider
- open_spider(spider) :能够在爬虫开启的时候执行一次
- close_spider(spider) :能够在爬虫关闭的时候执行一次
- 上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
中间件
根据scrapy运行流程中所在位置不同分为:下载中间件和爬虫中间件,两种中间件都在middlewares.py一个文件中
方法介绍
process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
- 返回Response对象:不再请求,把response返回给引擎
- 返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
- 返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
自定义中间件
在settings.py中添加
1
2
3
4
5
6
7
8
9
10
| USER_AGENTS_LIST = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
|
在middlewares.py中添加代码
1
2
3
4
5
6
7
8
9
10
11
12
13
| import random
from Tencent.settings import USER_AGENTS_LIST
class UserAgentMiddleware(object):
def process_request(self, request, spider):
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
class CheckUA:
def process_response(self,request,response,spider):
print(request.headers['User-Agent'])
return response
|
在settings.py中开启
1
2
3
4
| DOWNLOADER_MIDDLEWARES = {
'Test.middlewares.UserAgentMiddleware': 543,
'Test.middlewares.CheckUA': 600,
}
|
scrapy_splash
scrapy_splash是scrapy的一个组件
- scrapy-splash加载js数据是基于Splash来实现的。
- Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python和Lua语言实现的,基于Twisted和QT等模块构建。
- 使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后的网页源代码
docker安装
1
| docker run -d -p 8050:8050 scrapinghub/splash
|
访问 127.0.0.1:8050 查看
python使用
安装:pip install scrapy-splash
1
2
3
4
| scrapy startproject test_splash
cd test_splash
scrapy genspider no_splash baidu.com
scrapy genspider with_splash baidu.com
|
修改settings.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
SPLASH_URL = 'http://127.0.0.1:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
ROBOTSTXT_OBEY = False
|
使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import scrapy
from scrapy_splash import SplashRequest
class WithSplashSpider(scrapy.Spider):
name = 'with_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=13161933309']
def start_requests(self):
yield SplashRequest(self.start_urls[0],
callback=self.parse_splash,
args={'wait': 10},
endpoint='render.html')
def parse_splash(self, response):
with open('with_splash.html', 'w') as f:
f.write(response.body.decode())
|
总结
scrapy_splash组件的作用
- splash类似selenium,能够像浏览器一样访问请求对象中的url地址
- 能够按照该url对应的响应内容依次发送请求
- 并将多次请求对应的多次响应内容进行渲染
- 最终返回渲染后的response响应对象
scrapy_splash组件的使用
- 需要splash服务作为支撑
- 构造的request对象变为splash.SplashRequest
- 以下载中间件的形式使用
- 需要scrapy_splash特定配置
相关文章
Python基础
Python爬虫
Mongodb和Python交互
Python反爬解决方案
Python爬虫
Mongodb和Python交互
Python反爬解决方案
Python打包可执行文件


