MySql常用语法

最流行的开源数据库
SQL语句分类
DDL:数据定义语言,用来定义数据库对象:库、表、列等
DML:数据操作语言,用来定义数据库记录(数据)
DCL:数据控制语言,用来定义访问权限和安全级别;
DQL:数据查询语言,用来查询记录 select
CRUD
**C(Create)**:创建
**R(Retrieve)**:查询
**U(Update)**:修改
**D(Delete)**:删除
数据库操作
查看版本:select version();
显示当前时间:select now();
连接远程数据库:mysql -hip地址 -uroot -p
- -h后面写要连接的主机ip地址
- -u后面写连接的用户名
- -p回车后写密码
修改数据库访问权限
1 | |
创建数据库
1 | |
删除数据库
1 | |
切换数据库
1 | |
查看正在使用的数据库
1 | |
查看当前所有的数据库
1 | |
查看数据库基本信息
1 | |
修改数据库编码
1 | |
字段类型
整型

浮点型

字符串

时间日期

约束
主键
primary key
当某一列添加了主键约束后,那么这一列的数据就不能重复出现。这样每行记录中其主键列的值就是这一行的唯一标识。例如学生的学号可以用来做唯一标识,而学生的姓名是不能做唯一标识的,因为学习有可能同名。
主键列的值不能为NULL,也不能重复!
主键自增长:auto_increment
非空
not null
指定非空约束的列不能没有值,也就是说在插入记录时,对添加了非空约束的列一定要给值;在修改记录时,不能把非空列的值设置为NULL。
唯一
unique
还可以为字段指定唯一约束!当为字段指定唯一约束后,那么字段的值必须是唯一的。这一点与主键相似!例如给stu表的sname字段指定唯一约束
默认
default
外键
foreign key
主外键是构成表与表关联的唯一途径!
外键是另一张表的主键!例如员工表与部门表之间就存在关联关系,其中员工表中的部门编号字段就是外键,是相对部门表的外键。
数据表操作
查看数据库中所有表
show tables;
常见约束
含义:限制表中的数据,保证数据的一致性和准确性
| 约束 | 解释 |
|---|---|
| not null | 非空约束,表示字段不能为空 |
| default | 默认,用于使用默认值 |
| unique | 唯一约束,可以为空 |
| primary key | 主键约束,保证字段的唯一性,非空 |
| foreign key | 外键约束,用于限制两个表的关系 |
| check | 检查约束,MySQL不支持 |
约束分类
- 列级约束:支持默认,非空,主键,唯一,外键约束没有效果
- 表级约束:支持主键,唯一
创建表
使用
1 | |
1 | |
修改
alter table 表名 add |change| drop 列名 类型;
1 | |
删除
drop table 表名;
查看表结构
desc 表名;
更改表名称
rename table 原表名 to 新表名;
查看表的创建语
show create table 表名;
查询
条件查询
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字
=、!=、<>、<、<=、>、>=
BETWEEN…AND:是否满足一个区间范围
**IN(set)**:条件的集合
IS NULL
AND: 连接多个条件的查询
OR:or 满足其中一个条件就可以
NOT
模糊查询
当想查询姓名中包含a字母的学生时就需要使用模糊查询了。模糊查询需要使用关键字LIKE。
“_”匹配任意一个字母,5个“_”表示5个任意字母与汉字。
1 | |
%表示任意匹配字符
1 | |
distinct去重,查询表时出现重复时用
1 | |
给列起别名在字段后加 as 名字,可以省略as
1 | |
排序order by
升序:asc,降序:desc
order by后面支持放单个字段,多个字段,表达式,函数,别名
order by字句一般放在查询语句的最后面,limit除外
1 | |
分组函数
sum:求和
avg:求平均值
max:最大值
min:最小值
count:统计个数
sum和avg一般用于处理数值型
max和min和count支持处理任何类型
所有分组函数都忽略null值
在MYISAM引擎下使用count(*)效率最高,在INNODB引擎下count(*)和count(1)效率差不多
1 | |
分组查询
语法
1 | |
使用
1 | |
where和having
共同作用: 过滤掉不符合条件的数据
区别: where在GROUP BY之前,having在GROUP BY之后
where不能与组函数一块使用 having 可以
WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束
1 | |
关联查询
1 | |
连接查询
语法
1 | |
自连接:将同一张表视为多张表
内连接:inner join on,可以和where一起用
左外连接:left join on,不可以和where一起用
右外连接:right join on,不可以和where一起用
1 | |
子查询
含义:出现在其他语句中的select语句,外部的查询语句称为外查询或主查询
子查询可以出现的位置:select后面,from后面,where或having后面,exists后面
| 查询类名 | 含义 | 支持 |
|---|---|---|
| 标量子查询 | 结果集只有一行一列 | select,where或having后支持 |
| 列/多行子查询 | 结果集有一列多行 | where或having后支持 |
| 行子查询 | 结果集有一行多列 | where或having后支持 |
| 表子查询 | 结果集有多行多列 | from,exists后支持 |
1 | |
分页查询
语法
1 | |
Start 从第一行开始,默认索引为0
Rows 每次查询的行数
1 | |
联合查询
union:二个集合中,如果都有相同的,取其一
union all:二个集合中,如果都有相同的,都取
1 | |
增加
全列插入:insert into 表名 values(…);
缺省插入:insert into 表名(字段名,…) values(值1,…);
mysql特有的同时插入多条数据:insert into 表名 表名 values(…),(…)…;
或者:insert into 表名(列1,…) values(值1,…),(值1,…);
主键是自动增长,但是在全列插入时需要占位,通常使用0,插入成功后一实际数据为准
修改
updata 表名 set 列1=新值1,… where 条件;
删除
delete from 表名 where 条件;
逻辑删除
本质就是修改操作update (自己额外增加一个isdelete字段)
update 表名 set isdelete=1 where 条件;
1 | |
外键的级联操作
级联操作的类型包括
- **restrict(限制)**:默认值,拋异常
- **cascade(级联)**:如果主表的记录删掉,则从表中相关联的记录都会被删掉
- set null:将外键设置为空
- no action:什么都不做
最好的方法是做逻辑删除
注释
单行注释
– 注释内容 或者 # 注释内容(MySQL专用)
多行注释
/* 注释 */
函数
字符串函数
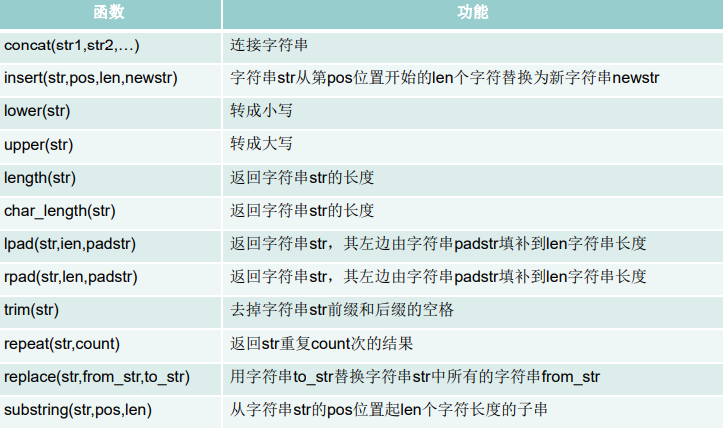
length:获取字符串字节个数
1 | |
concat:拼接字符串
1 | |
upper,lower:转换大小写
1 | |
substr,substring:截取字符串
1 | |
instr:返回子字符串所在的第一个索引,找不到返回0
1 | |
trim:去除前后空格或指定字符串
1 | |
replace:替换字符串
1 | |
lpad,rpad:用指定的字符填充左/右侧到指定长度
1 | |
数值类函数
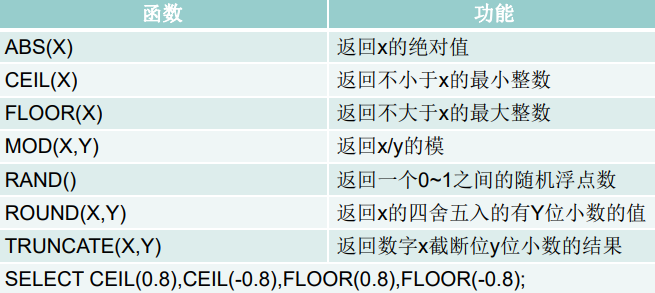
round:四舍五入
1 | |
ceil,floor:向上\下取整,返回大于\小于等于该参数的最小\大整数
1 | |
truncate:截断
1 | |
mod:取余,使用a-a/b*b计算
1 | |
时间和日期函数
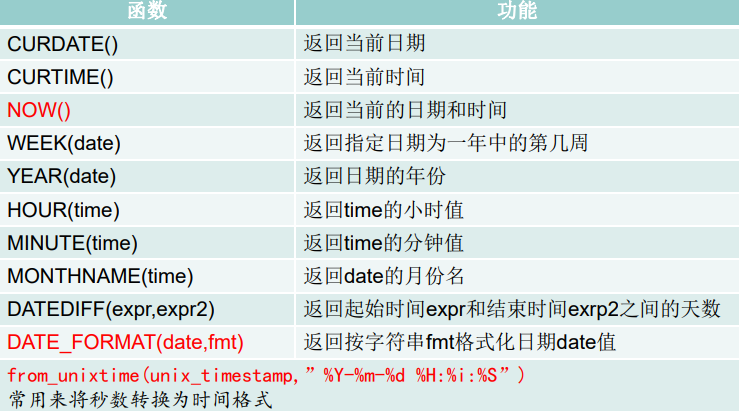

now:返回当前系统日期加时间
1 | |
curdate:返回当前系统日期,不包含时间
curtime:返回当前系统时间,不包含日期
1 | |
str_to_date:将字符转换为日期
1 | |
data_format:将日期转换为字符
1 | |
流程控制函数
if:判断效果,类似if…else
1 | |
事务
基本知识
概念:如果一个包含多个步骤的业务逻辑,被事务管理,那么这些操作要么同时成功,要么同时失败。
操作步骤:
- 开启事务:start transaction;
- 回滚事务:rollback;
- 提交事务:commit;
1 | |
MySQL数据库中事务默认是自动提交,一条DML(增删改)语句会自动提交一次事务
事务提交的两种方式
- 自动提交:MySQL默认自动提交
- 手动提交:Oracle默认手动提交,需要手动提交
修改事务的默认提交方式
- 查看事务的默认提交方式:SELECT @@autocommit; (1代表自动提交,0代表手动提交)
- 修改默认提交方式:SET @@autocommit = 0;
事务的四大特征
原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败
持久性:当事务提交或回滚后,数据库会持久化保存数据
隔离性:多个事务之间,相互独立
一致性:事务操作前后,数据总量不变
事务的隔离级别
概念:多个事务之间隔离的,相互独立的。但是如果多个事务操作同一批数据,则会引发一些问题,设置不同的级别就可以解决这些问题
存在问题
- 脏读:一个事务,读取到另一个事物中没有提交的数据
- **不可重复读(虚读)**:在同一个事务中,两次读取到的数据不一样
- 幻读:一个事务操作(DML)数据表中的所有记录,另一个事务添加了一条数据,则第一个事务查询不到自己的修改
隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 Read uncommitted | 有 | 有 | 有 |
| 读已提交 Read committed(Oracle默认) | 没有 | 有 | 有 |
| 可重复读 Repeatable read(MySQL默认) | 没有 | 没有 | 有 |
| 串行化/可序列化 Serializable | 没有 | 没有 | 没有 |
注意:隔离级别从小到大安全性越来越高,但效率越来越低
- 数据库查询隔离级别:select @@tx_isolation;
- 数据库设置隔离级别:set global transaction isolation level 级别字符串;
DCL
管理用户
添加用户
1 | |
删除用户
1 | |
修改用户密码
1 | |
查询用户
1 | |
MySQL忘记root密码
管理员权限打开cmd –> net stop mysql 停止MySQL服务
使用无验证方式启动MySQL服务:mysqld –skip-grant-tables
管理员权限打开新的cmd窗口,直接输入mysql命令就可以登录成功
1 | |
关闭两个窗口,打开任务管理器,手动结束mysqld.exe的进程
启动mysql服务:net start mysql,使用新密码登录
权限管理
查询权限
1 | |
授予权限
1 | |
撤销权限
1 | |
其他
设置sql自动递增初始值
1 | |
授权mysql远程登录
1 | |
查询语句顺序
1 | |
相关文章

